elasticsearch 向量检索相关知识点学习 | elasticsearch 技术论坛-金年会app官方网
参考资料
基本知识
向量数据库主要用于存储和查询高维向量,其核心功能是支持高效的向量相似度搜索。其中的知识点如下:
如何衡量 2 个向量相似?参考
- l2_norm,欧式距离,公式是
(x1-y1)^2 ... (xk-yk)^2的平方根 - cosine,余弦相似度,公式是
x1*y1 ... xk*yk除以||a||*||b|| - dot_product,点积,公式是
x1*y1 ... xk*yk
向量检索方式,假设向量维度为k,数量为n:
- brute-force,暴力检索,时间复杂度是o(n)
- k-dimension tree,基于特殊的二叉树,时间复杂度是o(log(n))
- ivf(inverted file system)
- pq(product quantizer)
- ivf-pq(inverted file system - product quantizer)
- lsh(locality sensitive hashing)
- hnsw(hierarchical navigable small worlds)
以上除了暴力检索,其他都属于ann(approximate nearest neighbor)的相似性检索算法,大体可以分为三大类:
- 基于树的方法,低维度的数据性能比较高效;高维度的数据性能较差
- 哈希方法,对于小数据集和中等数据集效果不错
- 矢量量化,对于大规模数据集,矢量量化是个很好的选择
brute-force
检索时,依次对每个数据进行相似度计算,返回最接近的值
k-dimension tree
存储过程:在第一维取中位值为根节点,分成左右两边数据,左边数据小于根节点,右边数据大于根节点。进入第二维,左右两边取第二维的中位值作为根节点,分成左右两边数据,此时第一维根节点分别指向左边根节点和右边根节点。依次递归,只到完成所有维度。代码实现如下:
class kdtreenode:
def __init__(self, point, split_dim=none, left=none, right=none):
self.point = point
self.split_dim = split_dim
self.left = left
self.right = right
def build_kdtree(points, depth=0):
n = len(points)
if n == 0:
return none
k = len(points[0]) # dimensionality of the points
# select the splitting dimension
split_dim = depth % k
# sort points along the selected dimension
points.sort(key=lambda point: point[split_dim])
# choose the median point
median = n // 2
# create the node and recursively build the left and right subtrees
return kdtreenode(
point=points[median],
split_dim=split_dim,
left=build_kdtree(points[:median], depth 1),
right=build_kdtree(points[median 1:], depth 1)
)
# example usage:
points = [(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)]
tree = build_kdtree(points)ivf
先通过聚类算法把数据分成m个子空间,检索的时候看查询的vector和那个子空间最相近,然后只在这个子空间内进行检索。代码实现如下:
import numpy as np
from sklearn.cluster import kmeans
def cosine_similarity(x, y):
num = x.dot(y.t)
norm = np.linalg.norm(x) * np.linalg.norm(y)
return num / norm
class vectorspacesearch:
def __init__(self, n_clusters):
self.n_clusters = n_clusters
self.kmeans = kmeans(n_clusters=n_clusters)
self.inverted_index = {}
def fit(self, x):
"""fit the model to the data x and build the inverted index."""
labels = self.kmeans.fit_predict(x)
for i, label in enumerate(labels):
if label not in self.inverted_index:
self.inverted_index[label] = []
self.inverted_index[label].append(x[i])
def search(self, query, similarity_func):
"""search for the most similar vector to the query."""
label = self.kmeans.predict(query.reshape(1, -1))
cluster = self.inverted_index[label[0]]
similarities = [similarity_func(query, x) for x in cluster]
return cluster[np.argmax(similarities)]
data = np.array([(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)])
vss = vectorspacesearch(3)
vss.fit(data)
query = np.array([(2, 3.1)])
result = vss.search(query, cosine_similarity)
print(result)pq
假设向量个数有n个,维度是128,维度切成m份,这样每份的维度就是128/m。然后每份又通过聚类算法分成256簇。每来一个查询向量,也先切成m份,再分别与这些簇的中心点计算距离,例如第一条距离等于l1 … lm。得到256条结果,取距离最近,得到m个簇,计算查询向量与这m个簇的簇内向量距离,取topn。
ivf-pq
参考和。假设簇心个数为1024,那么每来一个查询向量,首先计算其与1024个粗聚类簇心的距离,然后选择距离最近的top n个簇,只计算查询向量与这几个簇底下的向量的距离,计算距离的方法就是前面提到的pq。
lsh
参考
假设有数据集合中有6个点:a=(1,1) b=(2,1) c=(1,2) d=(2,2) e=(4,2) f=(4,3),01编码后是:
v(a)=10001000
v(b)=11001000
v(c)=10001100
v(d)=11001100
v(e)=11111100
v(f)=11111110
这里有2个参数:
l=3,表示hash表的个数
k=2,表示二进制的位数,它指示了每个hash表的簇数是k^2
假设3个hash表对应的3个hash函数如下:
g1分别取第2位,第4位
g2分别取第1位,第6位
g3分别取第3位,第8位
以元素a为例,按照规则g1(a)=00,g2(a)=10,g3(a)=00,其它依次类推,最后得到:
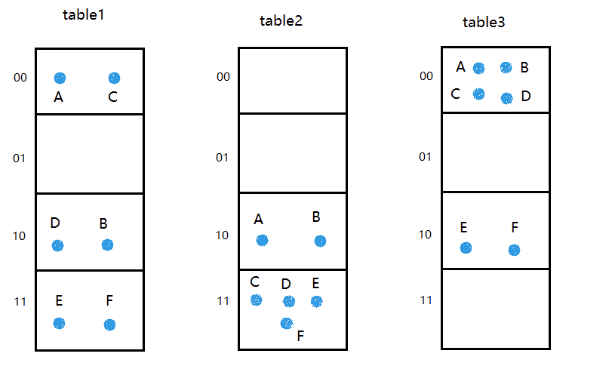
设查询向量q=(4,4)=(11111111),可以计算出g1(q)=11,g2(q)=11,g3(q)=11,然后从3个hash表对应的簇中取出所有元素,即c,d,e,f。
hnsw
思路与常见的跳表算法相似,如下图要搜索跳表,从最高层开始,沿着具有最长“跳过”的边向右移动。如果发现当前节点的值大于要搜索的值-我们知道已经超过了目标,因此我们会在下一级中向前一个节点。
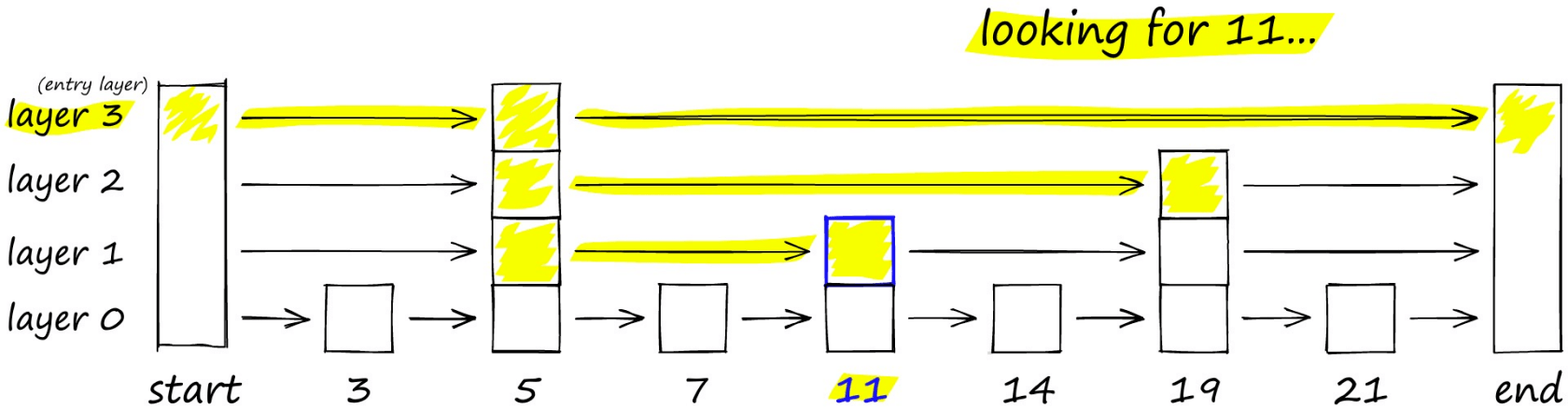
hnsw 算法是一种经典的空间换时间的算法,它的搜索质量和搜索速度都比较高,但是它的内存开销也比较大,因为不仅需要将所有的向量都存储在内存中。还需要维护一个图的结构,也同样需要存储。所以这类算法需要根据实际的场景来选择。
本作品采用《cc 协议》,转载必须注明作者和本文链接
