类 taskflow 框架性能年终 pk | go 技术论坛-金年会app官方网
开场白
临近元旦,又到了各个平台发年度报告的时间。刚好,离 ograph 第一次正式提交也过了差不多一年了,是骡子是马,咱也趁着这个热闹,拉出来溜溜。
还是先介绍一下 ograph 吧,这是一个基于dag图的任务流程执行框架。你可能听说过 taskflow,ograph 就是类似的框架。基本的使用方法如下:
func testhello(t *testing.t) {
pipeline := ograph.newpipeline()
zhangsan := ograph.newelement("zhangsan").usefn(func() error {
fmt.println("hello")
return nil
})
lisi := ograph.newelement("lisi").usefn(func() error {
fmt.println("hi")
return nil
})
pipeline.register(zhangsan).
register(lisi, ograph.rely(zhangsan))
if err := pipeline.run(context.todo(), nil); err != nil {
t.error(err)
}
}ograph 会按依赖关系,先执行 zhangsan 输出 hello, 再执行 lisi,输出 hi。
除了 usefn,按实际使用场景或者风格偏好,还可以使用 usenode,usefactory,这里就不详细展开了。
pk 嘉宾
作为老牌大哥,taskflow 的后来者当然不止 ograph。虽然风格和侧重场景有所不同,但是核心功能是一样的。
下面揭晓本次 pk 嘉宾:
首先是 cgraph🫡🫡🫡
想必你也发现了,ograph 名字和 cgraph 很相似。是的,ograph 确实在风格上 部分借鉴了 cgraph。当然在底层实现上还是完全不同的,毕竟一个是 c 写的,一个是 go 写的。
和一个多人开发,已经经过多年打磨的 c 项目比拼性能,还是挺有挑战性的,但也正因是因为这份挑战驱使我一次次优化性能。且看 ograph 是否能后来居上!
下一位来到战场的是:go-taskflow 🤟🤟🤟
想必聪明的你又发现了,go-taskflow 和 taskflow 名字很相似,风格上两者确实也很类似。
这个框架是我最近发现的,也是单人开发了差不多一年的 go 框架,从这点来说和 ograph 还挺像的。既然这么巧碰上了,那就不打不相识,一起来 pk 下吧。
至于为什么没有 taskflow 本尊呢?因为 cgraph 已经有和 taskflow 的性能测试对比了。从测试结果看,cgraph 性能已经领先 taskflow 了。有兴趣的小伙伴可以参考下,cgraph 作者的博客和b站视频:
pk 开始
这次 pk 使用的测试用例沿用 cgraph 作者的设计,是对框架核心调度性能的测试。
废话不多说,pk 这就开始。
round one
第一回合,考验各个框架的并发处理能力。
具体场景如下,有 32 个节点,这些节点之间没有任何依赖关系。因此在执行时候,这些节点是并发执行的。
每个框架各自执行 50 万次。
no.1 ograph
总耗时 2.17s
benchmarkconcurrent_32-8 500000 4331 ns/op 1592 b/op 16 allocs/op
pass
ok github.com/symphony09/ograph/test 2.170s
no.2 cgraph
总耗时 4.13s
**** running test-performance-01 ****
[2024-12-28 15:33:44.174] [test_performance_01]: time counter is : [4134.87] ms
no.3 go-taskflow
总耗时 9.71s
benchmarkc32-8 500000 19425 ns/op 7084 b/op 208 allocs/op
pass
ok github.com/noneback/go-taskflow 9.716s
round two
第二回合,考验各个框架对串行节点的执行优化。
具体场景如下,有 32 个节点,前后依次依赖(n1->n2->……->n32),因此在执行时候,节点是一个接一个执行。
每个框架各自执行 100 万次。
no.1 ograph
总耗时 0.29s
benchmarkserial_32-8 1000000 285.9 ns/op 120 b/op 4 allocs/op
pass
ok github.com/symphony09/ograph/test 0.290s
no.2 cgraph
总耗时 0.57s
**** running test-performance-02 ****
[2024-12-28 15:33:44.749] [test_performance_02]: time counter is : [572.61] ms
no.3 go-taskflow
总耗时 67.3s ?
go-taskflow 跑 100 万次时,出现卡死的情况。只能取跑 10 万次的耗时再乘 10。
benchmarks32-8 100000 67309 ns/op 6907 b/op 255 allocs/op
pass
ok github.com/noneback/go-taskflow 6.735s
round three
第三回合,考验各个框架对经典 dag 图的执行性能。
具体场景如下:
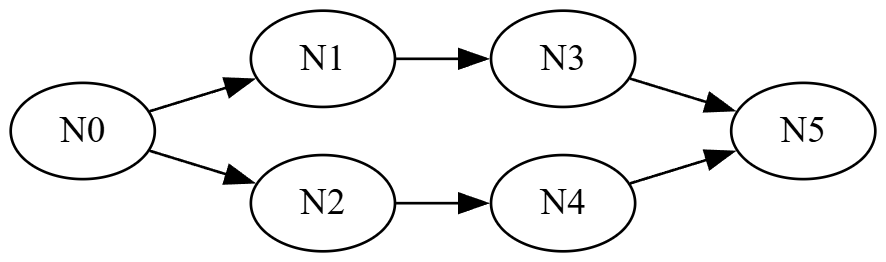
各个框架各执行 100 万次
no.1 ograph
总耗时 2.778s
benchmarkcomplex_6-8 1000000 2773 ns/op 1048 b/op 21 allocs/op
pass
ok github.com/symphony09/ograph/test 2.778s
no.2 cgraph
总耗时 4.027s
**** running test-performance-03 ****
[2024-12-28 15:33:48.778] [test_performance_03]: time counter is : [4027.31] ms
no.3 go-taskflow
总耗时 8.223s
benchmarkc6-8 1000000 8219 ns/op 1264 b/op 45 allocs/op
pass
ok github.com/noneback/go-taskflow 8.223s
round four
第四回合,考验各个框架对极多依赖的优化。
具体场景如下:8x8 全连接
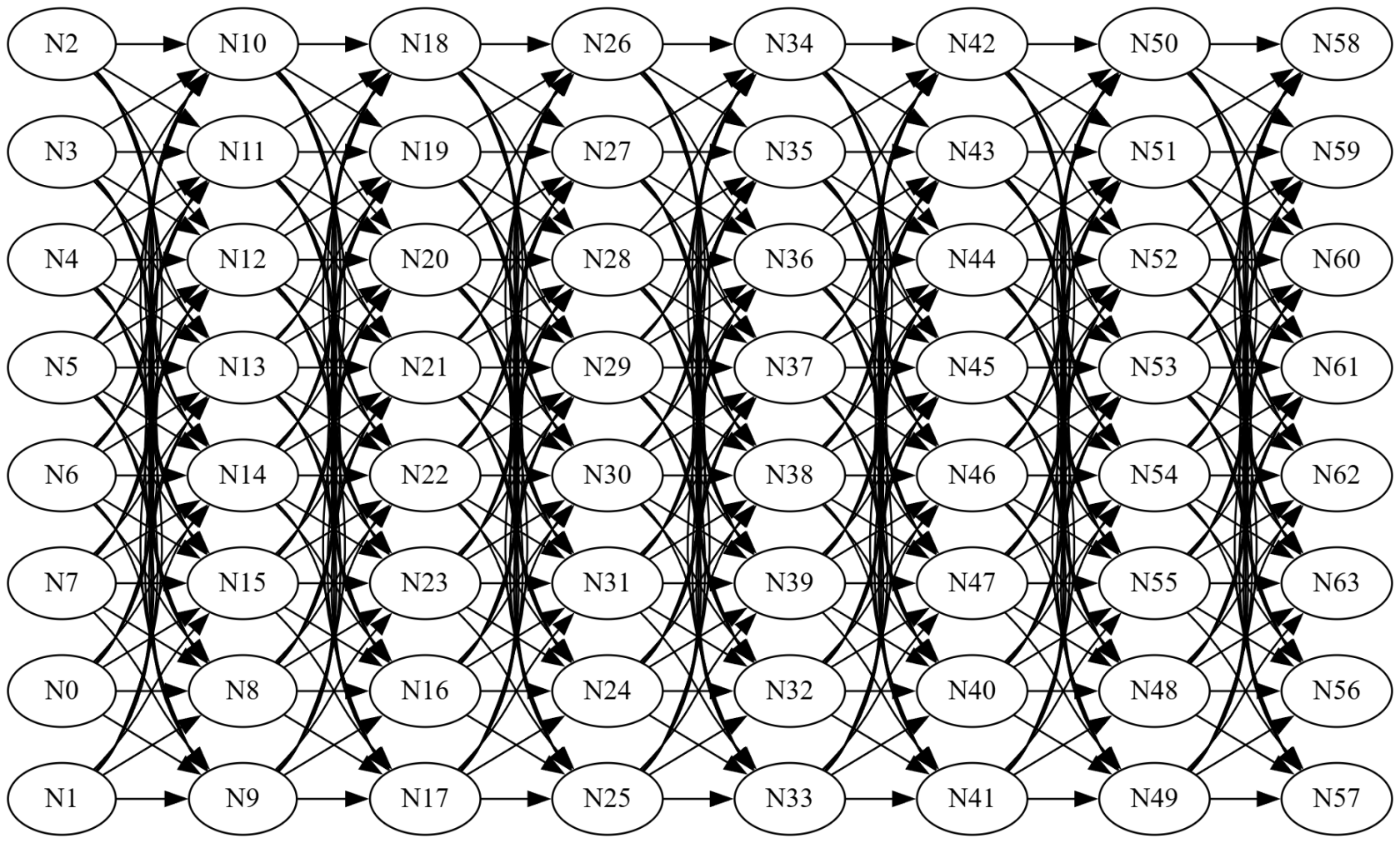
各个框架各执行 10 万次
no.1 ograph
总耗时 0.86s
benchmarkconnect_8x8-8 100000 8557 ns/op 2554 b/op 16 allocs/op
pass
ok github.com/symphony09/ograph/test 0.860s
no.2 cgraph
总耗时 1.357s
**** running test-performance-04 ****
[2024-12-28 15:33:50.137] [test_performance_04]: time counter is : [1357.03] ms
no.3 go-taskflow
总耗时 7.35s ?
又出问题了,故技重施
benchmarkc8x8
[panic] copool: node n24 ref counter is zero, cannot deref: goroutine 248743
结算

我宣布,ograph 《遥遥领先》😎😎😎。如果你也觉得 ok 的话,请给 ograph 一个 star!
附录
测试硬件
【cpu】amd 5600g - 6 核心 12 线程
【内存】ddr4 32 gb
测试软件
【系统】linux 6.11 - fedora workstation 41
【ograph】v0.6.1 - go 1.23.4
【cgraph】v2.6.2 - gcc14.2.1
【go-taskflow】v0.1.6 (master分支最新提交)
测试代码
【ograph】
【cgraph】
【go-taskflow】
func benchmarkc32(b *testing.b) {
tf := gotaskflow.newtaskflow("g")
for i := 0; i < 32; i {
tf.newtask(fmt.sprintf("n%d", i), func() {})
}
executor := gotaskflow.newexecutor(32)
for i := 0; i < b.n; i {
executor.run(tf).wait()
}
}
func benchmarks32(b *testing.b) {
tf := gotaskflow.newtaskflow("g")
prev := tf.newtask("n0", func() {})
for i := 1; i < 32; i {
next := tf.newtask(fmt.sprintf("n%d", i), func() {})
prev.precede(next)
prev = next
}
executor := gotaskflow.newexecutor(1)
for i := 0; i < b.n; i {
executor.run(tf).wait()
}
}
func benchmarkc6(b *testing.b) {
tf := gotaskflow.newtaskflow("g")
n0 := tf.newtask("n0", func() {})
n1 := tf.newtask("n1", func() {})
n2 := tf.newtask("n2", func() {})
n3 := tf.newtask("n3", func() {})
n4 := tf.newtask("n4", func() {})
n5 := tf.newtask("n5", func() {})
n0.precede(n1, n2)
n1.precede(n3)
n2.precede(n4)
n5.succeed(n3, n4)
executor := gotaskflow.newexecutor(1)
for i := 0; i < b.n; i {
executor.run(tf).wait()
}
}
func benchmarkc8x8(b *testing.b) {
tf := gotaskflow.newtaskflow("g")
layerscount := 8
layernodescount := 8
var curlayer, upperlayer []*gotaskflow.task
for i := 0; i < layerscount; i {
for j := 0; j < layernodescount; j {
task := tf.newtask(fmt.sprintf("n%d", i*layerscountj), func() {})
for i := range upperlayer {
upperlayer[i].precede(task)
}
curlayer = append(curlayer, task)
}
upperlayer = curlayer
curlayer = []*gotaskflow.task{}
}
executor := gotaskflow.newexecutor(8)
for i := 0; i < b.n; i {
executor.run(tf).wait()
}
}本作品采用《cc 协议》,转载必须注明作者和本文链接
